
È uscita da pochissimo la nona edizione della Mappa dell’Intolleranza, il progetto di Vox Diritti in collaborazione con l’Università degli Studi di Milano che dal 2016 monitora il discorso d’odio sui social media italiani. Quest’anno l’analisi copre 2 milioni di contenuti estratti dalla piattaforma X nel periodo gennaio–novembre 2025, classificati in sei categorie: misoginia, antisemitismo, xenofobia, islamofobia, abilismo e omo-lesbo-bi-trans-fobia.
La nuova edizione introduce novità importanti rispetto alle precedenti: un’analisi delle dinamiche di viralizzazione, uno studio sulla deumanizzazione, e un approfondimento sulle forme dirette e indirette del discorso d’odio.
Questi contributi rendono il progetto unico nel panorama italiano. Tuttavia, i limiti metodologici del report meritano un’analisi critica: un punto di riferimento sul tema dovrebbe essere il primo a porsi queste domande.
I numeri in breve
La distribuzione complessiva non sorprende: il 56% dei contenuti rilevati è classificato come negativo (era il 57% nel 2024), il 40% neutro, il 4% positivo. L’odio online, concludono i ricercatori, è un fenomeno strutturale.
Per categorie, la misoginia resta al primo posto con il 37% dei contenuti negativi (era il 50% nel 2024). L’antisemitismo sale dal 27% al 29%, xenofobia e islamofobia si attestano entrambe al 13%, abilismo al 5% e omotransfobia al 3%.
Aspetti interessanti
Il genere degli “odiatori”
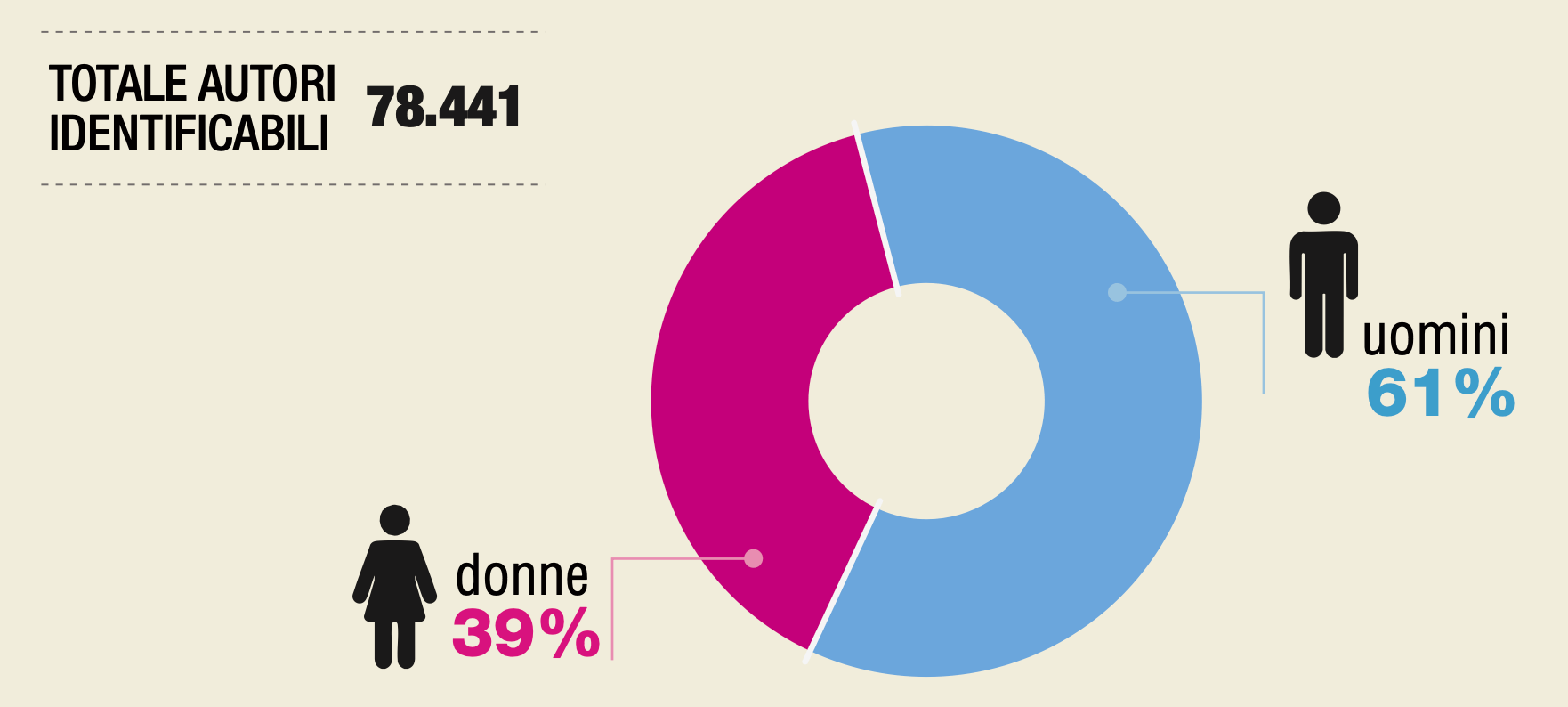
Uno dei dati più interessanti riguarda il genere degli autori dei contenuti ostili. Su 78’441 profili con genere identificabile, il 61% è maschile e il 39% femminile. Ma nella categoria misoginia, la quota femminile sale al 43% – quasi in parità con gli uomini.
Un dato che vale la pena approfondire con un po’ di aritmetica. Se le donne rappresentano il 39% degli autori identificabili ma producono il 43% dei contenuti misogini, significa che in proporzione alla loro presenza nel corpus, le donne producono più contenuti classificati come misogini rispetto agli uomini. Inversamente, la quota maschile nella misoginia (57%) è inferiore alla loro presenza complessiva nel campione.
Riguardo alla viralità: i contenuti pubblicati da account femminili generano in media 7.04 interazioni, contro le 6.11 degli account maschili – una capacità di circolazione superiore del 15%.
Il rapporto interpreta la partecipazione femminile alla misoginia attraverso il concetto di “auto-oggettivazione”, ossia l’idea che le donne interiorizzino lo sguardo maschile e riproducano verso altre donne gli stessi meccanismi di svalutazione.
È una spiegazione possibile, ma non l’unica. Forse le donne sono capaci di cattiveria autonoma, senza dover invocare l’interiorizzazione del patriarcato per giustificare ogni condotta. Non tutto il male che le donne fanno ad altre donne è necessariamente un riflesso della misoginia maschile – a volte è competizione, rivalità, antipatia, crudeltà ordinaria.
Considerare la donna sempre vittima, anche quando è lei stessa autrice di odio, infantilizza la sua agentività riducendola a mero riflesso di influenze esterne.
Le reti di amplificazione
Particolarmente interessante – ma purtroppo poco approfondita – è la sezione sulla viralizzazione.
Gli autori osservano che i contenuti negativi non si diffondono in modo casuale: l’amplificazione avviene ripetutamente attraverso gli stessi account, con un livello di concentrazione che definiscono “incompatibile con una diffusione spontanea”, suggerendo l’esistenza di reti strutturate nella propagazione dell’odio.
Il report nota anche che l’account più prolifico dell’intero corpus – responsabile oltre 2000 contenuti, di cui quasi 1600 classificati come hate speech – è un profilo anonimo. Questo apre domande enormi: chi c’è dietro questi account? Si tratta di un bot? Forse una rete di troll organizzati? O magari semplici individui con molto tempo libero?
Purtroppo il report non approfondisce, limitandosi a osservare il fenomeno senza tentare di spiegarlo. Eppure questa sarebbe a mio avviso la direzione di ricerca più urgente, e anche più interessante per analizzarne le dinamiche specifiche: capire chi orchestra la diffusione dell’odio online è almeno altrettanto importante quanto misurarne il volume.
La deumanizzazione
La novità più ambiziosa dell’edizione è l’analisi sulla deumanizzazione, condotta dai professori Inghilleri e Rainisio dell’Università di Milano su un corpus di oltre 26mila tweet.
Emerge che la deumanizzazione è presente in oltre un terzo dei contenuti analizzati, con “grammatiche” specifiche per ogni categoria: biologizzazione per l’abilismo (76,4%), animalizzazione per la xenofobia (71%), oggettivazione per la misoginia (44.5%).
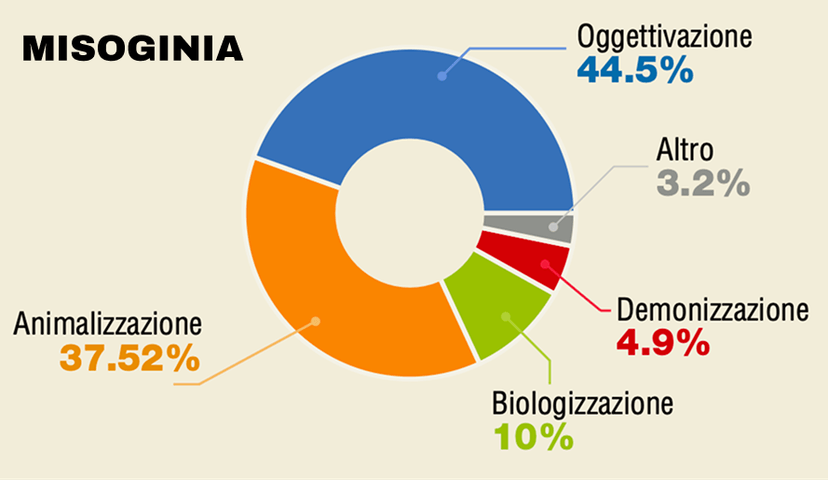
Un risultato rilevante riguarda l’islamofobia: i riferimenti alla supposta disumanizzazione interna all’Islam – la sottomissione della donna, la sharia – vengono usati come argomento retorico per legittimare la deumanizzazione dei musulmani. In pratica, accusare l’altro di disumanizzare diventa il presupposto per disumanizzarlo a propria volta. È un meccanismo retorico interessante e ben documentato.
I problemi
1. Nessuna definizione operativa
In un report di 70 pagine che classifica 2 milioni di contenuti in categorie come “misoginia”, “hate speech” e “stereotipo”, ci si aspetterebbe di trovare definizioni operative chiare di questi concetti. Non ci sono.
Cosa conta come “misoginia”? Un insulto diretto a una donna? Un insulto sessista rivolto a un uomo? L’uso della parola “troia” in qualsiasi contesto?
Cosa distingue l’hate speech dallo stereotipo? E il contenuto “neutro” da quello “negativo”?
Il report definisce l’hate speech come “una concreta istigazione all’odio e, in casi estremi, alla violenza”, e gli stereotipi come “scorciatoie cognitive per l’informazione basata su categorie” [Fiske 2000]. Entrambe sono definizioni teoriche, non operative. Come viene tradotta questa distinzione in criteri applicabili a un tweet di 280 caratteri? Non è dato saperlo.
A questo proposito, il report afferma che gli stereotipi indiretti sono
difficili da riconoscere come discriminatori anche per chi li riceve.
L’osservazione è presentata come accessoria, ma solleva una domanda fondamentale: se chi riceve un messaggio non lo percepisce come discriminatorio, su quale base lo classifichiamo come hate speech? È il classificatore automatico a decidere cosa è odio, anche quando né chi lo scrive né chi lo legge lo interpreta come tale?
2. L’algoritmo fantasma
La nota metodologica ci dice che i contenuti sono stati classificati tramite “Large Language Models (LLM) attraverso un prompt standardizzato” che prevedeva
l’analisi del linguaggio, l’identificazione di parole chiave, la spiegazione del ragionamento, la definizione dei target e la valutazione della directness.
È tutto ciò sappiamo: un’informazione decisamente insufficiente 1.
Quale LLM? GPT-4? Claude? Un modello open-source messo a punto e ottimizzato per questo scopo?
Poi, quali prompt sono stati utilizzati esattamente? Con quali criteri di classificazione? Qual è la precisione del modello? Quanti contenuti sono stati rivisti manualmente, e su quanti il classificatore automatico e i revisori umani concordavano?
Lo stesso documento riconosce alcune limitazioni importanti:
l’analisi linguistica è intervenuta a valle della classificazione automatica, senza possibilità di intervento sul processo di categorizzazione
E poi:
i singoli post sono stati analizzati come unità isolate, senza accesso al thread originale, riducendo le inferenze possibili sul contesto discorsivo più ampio.
Il rapporto ammette questi limiti nelle note metodologiche, ma li ignora quando presenta i risultati come fatti acquisiti nelle sezioni precedenti.
3. Il problema del contesto
Come appena visto, il report stesso ammette che i singoli post sono stati analizzati in modo isolato, senza accesso al thread originale. Ma come si può stabilire che un tweet è effettivamente misogino senza il contesto in cui è stato scritto?
Prendiamo uno degli esempi menzionati:
«Ma perché ti copri il viso? Prima fate le zoccole e dopo vi vergognate».
Senza contesto – chi parla, a chi, in risposta a cosa – è impossibile determinare con certezza se si tratti di un commento misogino verso una persona specifica, di una battuta (di dubbio gusto) tra amici, o magari di una citazione ironica. Il report lo presenta come esempio di stereotipo misogino mappato, senza ulteriori qualificazioni.
Lo stesso vale per l’abilismo: se qualcuno scrive “solo un cerebroleso voterebbe per X”, è certamente un insulto e un uso abilista del linguaggio. Ma l’intento dell’autore non è probabilmente discriminare le persone con disabilità cognitive – è insultare un avversario politico.
Il report riconosce questa dinamica e la chiama “normalizzazione”: molti insulti sessisti e abilisti si sono sedimentati nel linguaggio comune, svincolandosi dal loro riferimento originario. Tuttavia, anziché trattare questo come un problema metodologico che influenza l’interpretazione dei dati, lo tratta come un risultato – nonché come una conferma della gravità del fenomeno.
4. La tesi della “normalizzazione”
Il concetto-chiave del report sulla misoginia – che il calo percentuale dal 50% al 37% non indica una diminuzione ma una “normalizzazione” – viene ripetuto quasi identico almeno quattro volte nel documento, ma non viene mai dimostrato empiricamente.
La tesi è: gli insulti sessisti si sono svincolati dal riferimento originario alle donne e sono diventati insulti generici, quindi il classificatore li intercetta di meno, ma la misoginia è in realtà più pervasiva che mai.
Il ragionamento però rischia concretamente di diventare circolare: se i dati scendono, è perché il fenomeno si è “nascosto” ed è più difficilmente individuabile; se i dati salgono, è perché il fenomeno è cresciuto. La tesi, di fatto, è infalsificabile.
I dati storici dalle Mappe precedenti rendono la tesi ancora meno convincente. La percentuale di misoginia sul totale dei contenuti negativi ha oscillato in modo importante nel corso delle nove edizioni: 60-63% nel 2016-18, 32% nel 2019, 50% nel 2020, 43% nel 2021-22, 50% nel 2024, 37% nel 2025. Un andamento a yo-yo, con variazioni di oltre 20 punti percentuali da un’edizione all’altra.
Ammesso che le rilevazioni siano state fatte nello stesso modo e le variazioni non siano dovute a un cambio di metodologia, se la “normalizzazione” fosse davvero un processo di sedimentazione graduale nel linguaggio comune, ci aspetteremmo un calo tendenziale costante – non salti dal 30% al 50% e ritorno.
Queste oscillazioni suggeriscono piuttosto che la percentuale di misoginia sia influenzata da fattori congiunturali – eventi di cronaca, dibattiti pubblici, cambiamenti nell’algoritmo della piattaforma – più che da una trasformazione culturale profonda.
Il report cita anche il lavoro di Raffaella Scarpa [Scarpa 2024] sulla “grammatica dell’abuso” per suggerire che esista un sommerso di misoginia non rilevabile dagli strumenti automatici. Ma il ragionamento è anche qui circolare: si ammette che i propri strumenti non sono in grado di misurare queste forme sottili, e poi si conclude che proprio per questo il fenomeno è probabilmente più grave di quanto i dati mostrino. È un’affermazione non falsificabile – e in quanto tale, non possiamo considerarla “scienza”.
Per sostenere empiricamente questa affermazione, servirebbero almeno:
- un confronto diacronico sull’uso dei lemmi sessisti come insulti generici (sono aumentati nel tempo?);
- un’analisi del target effettivo degli insulti (a chi sono rivolti?)
- un tentativo di distinguere l’uso misogino da quello genericamente offensivo.
Il documento, tuttavia, omette tali analisi.
Mentre leggevo, infine, mi è venuto in mente un parallelismo, frutto di svariate discussioni in famiglia e nei circoli di confronto “atei vs credenti” a cui ho partecipato negli anni: soprattutto in regioni come Veneto e Toscana, le bestemmie in italiano sono spesso usate come intercalare, completamente svuotate del loro contenuto religioso.
Se contassimo tutti i tweet con bestemmie e li classificassimo come “odio anticristiano”, otterremmo numeri impressionanti – ma a quel punto dovremmo aggiungere una dimensione alla nostra “mappa dell’intolleranza”, dato che ci troveremmo davanti a una presenza notevole e probabilmente preoccupante di anticlericalismo. Se invece scegliamo di rimanere più ancorati alla realtà (e personalmente preferisco così), concluderemmo semplicemente che la volgarità è potente negli italiani.
5. Il cambio di base nei dati di genere
Un dettaglio tecnico che il report non segnala esplicitamente e che rischia di confondere il lettore (e in effetti ha confuso almeno un paio di testate giornalistiche che hanno commentato la nuova Mappa dell’Intolleranza): i dati sul genere degli autori del 2024 e del 2025 non sono direttamente confrontabili.
Nell’edizione 2024, le percentuali di genere erano calcolate sull’intero corpus dei tweet (inclusi gli account con genere non identificabile). Nel 2025, i dati si riferiscono esplicitamente ai 78.441 profili con genere identificabile, escludendo gli account anonimi.
Questo cambio di base rende il confronto anno su anno fuorviante, perché le percentuali 2025 sono meccanicamente più alte per entrambi i generi rispetto a quelle che si otterrebbero calcolandole con la stessa base dell’anno precedente.
In pratica no, la percentuale di tweet misogini da parte di account femminili non è raddoppiata (dal 20% al 43%) in un anno; piuttosto, si è dimezzato il denominatore.
6. Le word cloud: un’occasione sprecata
Le sezioni “Top Topics” e “Trending Topics” per ogni categoria presentano word cloud che includono termini come “qualcosa”, “nonostante”, “comunque”, “esempio”, e persino connettori come “ce”, “se”, “sa”, “sto”. Si tratta di parole vuote – congiunzioni, pronomi, avverbi generici – che qualsiasi analisi testuale di base filtrerebbe prima di produrre una visualizzazione.
La loro presenza nel risultato finale suggerisce o un’assenza di filtraggio linguistico (improbabile, dato il livello della ricerca) o una scelta deliberata di non eliminare queste parole – in entrambi i casi, il risultato è che le nuvole risultano poco informative e rischiano di compromettere la credibilità di un’analisi per il resto sofisticata.
Peccato, perché delle word cloud ben costruite avrebbero potuto compensare uno dei limiti più evidenti: la scarsità di esempi concreti. I tweet riportati come campione sono pochissimi – e peraltro identici a quelli della scorsa edizione – e il lettore resta con poca idea di quali termini e costruzioni il classificatore consideri effettivamente misogini, abilisti o xenofobi.
Una visualizzazione pulita dei lemmi discriminatori più ricorrenti per categoria sarebbe stata molto più utile di una nuvola piena di “comunque” e “nonostante”.
7. Il dato “85 donne vittime” e l’incidenza “una su tre”
Il documento cita, nel contesto dei picchi di hate speech misogino:
Tra gennaio e ottobre 2025, 85 donne vittime di omicidio volontario in Italia: la più alta incidenza mai registrata, oltre una su tre.
Il dato meriterebbe un chiarimento. “Una su tre” rispetto a cosa? Al totale delle vittime di omicidio volontario?
Consultando i dati del Ministero dell’Interno per il 2025, risultano effettivamente 85 donne uccise in ambito familiare o affettivo, che rientrano nella definizione più comune di femminicidio. Tuttavia la Mappa parla di “vittime di omicidio volontario”, che secondo il rapporto sopracitato sarebbero 97 (un omicidio di una donna non è per forza un femminicidio), e 85 su 97 sono quasi 9 su 10, ben più di una su tre.
Forse gli autori si sono confusi con la celebre frase “una donna uccisa ogni tre giorni”?
Non mi risulta neanche che nel 2025 ci sia stata “la più alta incidenza mai registrata”, considerando che il fenomeno è sostanzialmente stabile da parecchi anni, e ISTAT ne rileva di più già nel 2024.
In un contesto così delicato, la precisione non dovrebbe essere un optional.
Cosa manca
Al di là dei problemi specifici, ci sono alcune assenze che a mio avviso pesano sull’intero impianto del rapporto.
Confronto con il linguaggio non discriminatorio
Il report analizza 2 milioni di contenuti estratti con chiavi di ricerca specifiche progettate per intercettare hate speech. Ma senza un campione di controllo – lo stesso tipo di linguaggio usato in contesti non discriminatori – è impossibile sapere se ciò che il classificatore intercetta è davvero discriminazione o semplicemente volgarità, conflittualità interpersonale, o uso decontestualizzato di parole che possono essere discriminatorie ma non lo sono in modo intrinseco.
Soglia di significatività
La ricerca presenta percentuali con due decimali (5.42% di stereotipi puri, 4.79% di misti) senza mai discutere la significatività statistica dei risultati né gli intervalli di confidenza. Con un corpus di 2 milioni di contenuti, quasi tutto è “statisticamente significativo” – il che rende il concetto poco utile, ma non esime dal discuterne.
Analisi della misandria
Hear me out, prometto che non si tratta di una lamentela benaltrista alla “E allora gli uomini??”
Con i (purtroppo pochissimi) esempi riportati, ma anche considerando le misure di oggettivazione, bestializzazione, deumanizzazione ecc., è facile immaginare esempi degli stessi insulti e meccanismi denigratori applicati in modo speculare al genere maschile.
Uomini ridotti a un’estensione del loro organo riproduttivo? Definiti “porci”, “cani”, “bestie non in grado di controllare i loro istinti sessuali” o al contrario “sfigati che odiano le donne che non gliela danno”? Non sono commenti rari in cui imbattersi su internet, e per quanto la misandria online sia un fenomeno meno studiato del corrispettivo femminile, non mancano per fortuna ricerche che hanno iniziato ad analizzarlo come un possibile pattern ricorrente (es. [Coppolillo 2025]).
E gli specchi sono ovunque, se si ha voglia di guardarli.
- “Cornuto” riduce l’uomo al suo ruolo sessuale e relazionale esattamente come “zoccola” fa con la donna – eppure nessuno lo classificherebbe come hate speech misandrico.
- “Impotente” ed “eunuco” funzionano come speculare di “isterica”: riducono la persona a una presunta disfunzione biologica legata al sesso.
- “Mandrillo” è un equivalente maschile di “troia” – bestializzazione della sessualità – ma con una connotazione quasi goliardica che il femminile non ha.
In sostanza, la nostra Mappa dell’Intolleranza dedica pagine intere alla misoginia, ma non esiste una categoria equivalente per l’odio diretto contro gli uomini. Questo non significa che i due fenomeni siano equivalenti in gravità o diffusione, ma l’assenza totale di un confronto rende impossibile capire se certi schemi – per esempio l’uso di ingiurie legate alla sfera sessuale come insulti generici – siano specifici del discorso sulle donne o trasversali al discorso d’odio in generale.
Se “figlio di puttana” è un lemma misogino, “testa di cazzo” e “coglione” sono lemmi misandrici? E se non lo sono, perché?
La scelta di quali categorie monitorare non è neutra. Includere la misoginia ed escludere la misandria, o includere l’islamofobia ed escludere la cristianofobia2, sono decisioni che riflettono un framework interpretativo preciso: quello per cui esistono gruppi strutturalmente oppressi e gruppi strutturalmente dominanti, e solo l’odio verso i primi merita di essere misurato.
Il report, va detto, non nasconde per niente il proprio impianto teorico – il riferimento esplicito all’intersezionalità ne chiarisce la cornice. Ma una cosa è dichiarare il proprio quadro analitico, un’altra è discutere le conseguenze delle sue esclusioni.
Perché la misandria non è una categoria monitorata? Perché la cristianofobia no? Sono scelte legittime, ma andrebbero motivate – perché influenzano tutto il resto: cosa si cerca, cosa si trova, cosa si conclude.
Sempre a proposito del campione di controllo menzionato in questa sezione, a mancanza di una categoria “speculare” impedisce di capire se l’odio sia diretto al genere o se sia una manifestazione di conflittualità generale online.
Se avessimo una Mappa che include anche gli insulti sessisti verso gli uomini, potremmo scoprire che la “normalizzazione” del linguaggio sessista è un fenomeno simmetrico – che “coglione” si è svuotato del suo riferimento anatomico esattamente come “troia”. Oppure potremmo scoprire che non lo è, e che c’è davvero un’asimmetria misurabile. Ma senza cercare, non possiamo saperlo, e non cercare a volte è già una risposta.
In sintesi
Al di là di tutti i limiti evidenziati, trovo che la Mappa dell’Intolleranza sia un progetto importante per il panorama italiano. Ha il merito della continuità (nove edizioni), dell’ambizione interdisciplinare e dell’introduzione di analisi innovative come quella sulla deumanizzazione, ed è probabilmente lo strumento più strutturato di monitoraggio dell’hate speech online che esista nel nostro paese.
Proprio perché si propone come punto di riferimento, però, dovrebbe essere tenuta a standard più alti.
L’opacità metodologica – in particolare sull’algoritmo di classificazione e sulle definizioni operative – è a mio avviso un problema serio. La tesi della “normalizzazione” della misoginia è presentata come fatto acquisito ma non è sostenuta da evidenze specifiche. Il problema del contesto è riconosciuto ma non affrontato. E l’assenza di un corpus di controllo rende difficile interpretare i risultati al di là del loro valore nominale.
Sia chiaro che niente di tutto questo, per quanto mi riguarda, invalida il lavoro svolto. Significa semplicemente che i risultati vanno letti con più cautela di quanta il report stesso ne suggerisca – e che alcune delle conclusioni più forti meriterebbero una base empirica più solida.
P.S.: Ho scritto ai ricercatori per chiedere dettagli sulla metodologia AI. Se riceverò risposta, aggiornerò senz’altro questo articolo o ne pubblicherò uno nuovo.
Bibliografia
[Coppolillo 2025] Elena Coppolillo, Women who hate men: a comparative analysis across extremist Reddit communities. Sci Rep 5, 2025 ^
[Fiske 2000] S. T. Fiske, Stereotyping, prejudice, and discrimination, The hand-book of social psychology (4th ed., Vol. 2, pp. 357–411), McGraw-Hill 2000 ^
[Scarpa 2024] Raffaella Scarpa, Lo stile dell’abuso. Violenza domestica e linguaggio, Treccani Libri, 2024 ^
Note
Footnotes
-
Soprattutto la sottoscritta, che lavora nell’ambito informatico e, seppure non impiegata direttamente nel settore dell’intelligenza artificiale deve sapere come sono state fatte le cose col maggior livello di dettaglio possibile. Perché mi fate questo, perché? 😢 ↩
-
Lieta di presentarvi (o di sbloccarvi il ricordo, nel caso lo conosciate già) il meraviglioso libro Omofobia o eterofobia?, in cui l’avv. Amato porta avanti la tesi secondo cui in Italia sarebbero le persone etero – e non la comunità LGBT – quelle discriminate.
Si tratta di una tesi che, per dirla con un eufemismo, non trovo convincente, né facilmente estendibile ad altri casi (ad esempio ipotizzando che le persone abili o cisgender subiscano forme di discriminazione). Tuttavia, da persona che ha frequentato ambo gli “schieramenti” (i.e. cattolica praticante da bambina, ora atea anticlericale e pure sbattezzata), ritengo avrebbe senso analizzare per esempio l’incidenza sia dei tweet con sentimenti anti-credenti sia quelli anti-atei, se non altro per curiosità. ↩